Introducing RadixAttention to Trellis
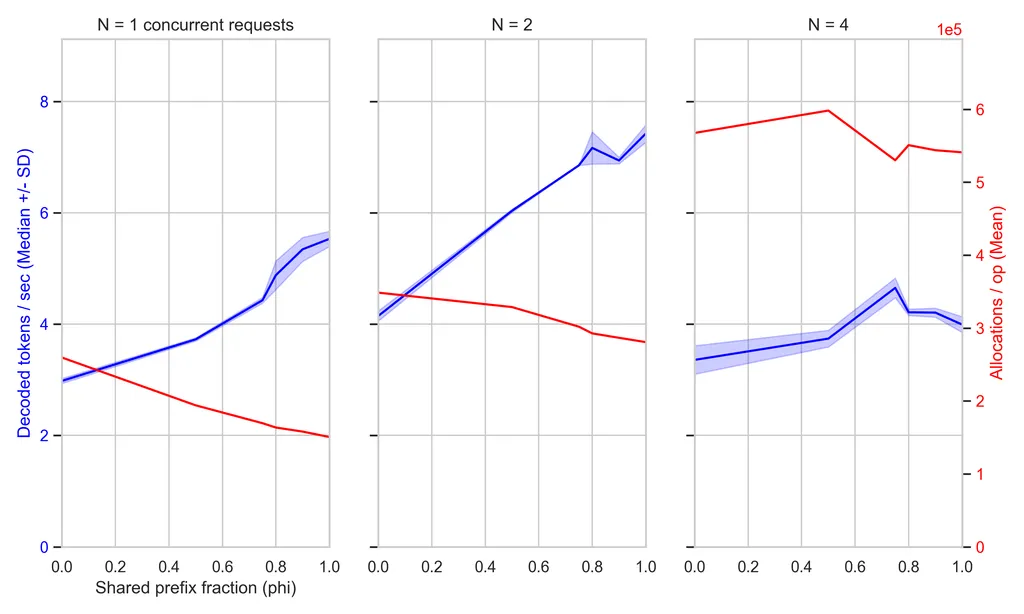
Trellis has been developed to enhance LLM inference while ensuring user data privacy. The system allows deployment on existing hardware and optimizes the prefill phase of LLM inference using a caching strategy. The introduction of RadixAttention improves efficiency by caching common prefixes in chat-based sessions.
- ▪Trellis enables LLM inference on user-owned hardware like laptops and servers.
- ▪RadixAttention utilizes a radix tree to optimize storage for shared string prefixes.
- ▪The KV caching mechanism in Trellis enhances concurrency by allowing multiple sessions to share prefix blocks.
Opening excerpt (first ~120 words) tap to expand
We created Trellis to democratize LLM inference without making compromises on the data privacy of its users. Towards that goal, we built a system that users can deploy on hardware they already own and operate, i.e. laptops, workstations and servers alike. To meet users where they are, we must accommodate more or less performant hardware, and therefore take optimization opportunities whenever possible. In this post, we will focus on how we optimized the prefill phase of LLM inference in Trellis. We'll start by giving a brief background on the problem, discuss our implementation of a caching strategy that is relevant for chat-based and agentic LLM sessions, and conclude by showing some benchmark results.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Trellis.
Discussion
0 commentsMore from Trellis



