I Built a C++ Backend So My GPU Would Stop Eating Air
The article discusses the development of the WarpGroup-Backend, a C++ engine designed to optimize GPU performance by eliminating padding overhead in machine learning tasks. It highlights how traditional methods waste computational resources by padding variable-length sequences with zeros. The new approach significantly increases throughput and reduces out-of-memory crashes while maintaining efficiency.
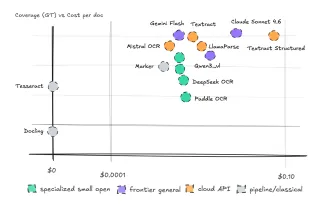
- ▪WarpGroup-Backend replaces padding with a C++ engine that efficiently packs variable-length sequences for GPU processing.
- ▪The new method achieves 2.08× throughput on an H100 and 5.89× on a GTX 1080, while preventing out-of-memory crashes.
- ▪Traditional LLM batching pads sequences to the longest one, leading to wasted computational resources.
Opening excerpt (first ~120 words) tap to expand
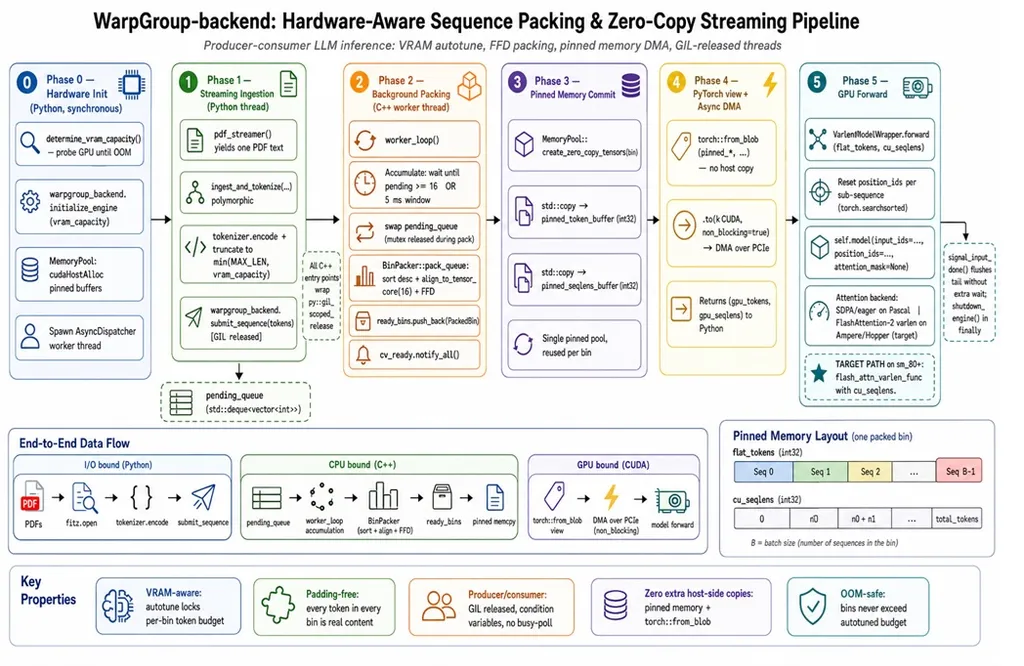
Machine Learning I Built a C++ Backend So My GPU Would Stop Eating Air How to eliminate padding overhead and accelerate LLM inference at the hardware level. Anubhab Banerjee Jun 3, 2026 31 min read Share WarpGroup-Backend pipeline architecture — Phase 0 hardware autotune, Phase 1 Python ingestion, Phase 2 C++ background packing, Phase 3 pinned memory commit, Phase 4 PyTorch view and async DMA, Phase 5 GPU forward pass, with end-to-end data flow (Python I/O → C++ CPU → CUDA GPU) and pinned-memory layout diagrams. Image created with Claude 4.7 Opus. This is a humorous-but-real tour of the WarpGroup-Backend — covering VRAM-aware bin packing, pinned-memory transfers, and how to make your LLM up to 5.89× faster by being mildly rude to PyTorch.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Towards Data Science.
Discussion
0 commentsMore from Towards Data Science