Going from 3B/7B dense to Nemotron 3 Nano (hybrid Mamba-MoE) for multi-task reasoning — what changes in the fine-tuning playbook? [D]
·
0 reactions
·
0 comments
·
2 views
Following up on something I posted a few days back about fine-tuning for multi-task reasoning. Read a lot since then, and I've moved past the dense 3B vs 7B question — landing on Nemotron 3 Nano (the 30B-A3B hybrid Mamba-Attention-MoE NVIDIA released recently) instead. Architecture maps to the multi-task structure I'm trying to train better than a dense base. Problem is I've only ever read about dense transformer fine-tuning, so I don't know what the hybrid Mamba+MoE arch actually breaks in the
Original article
Machine Learning
Anonymous · no account needed
Discussion
0 commentsMore from Machine Learning

US Supreme Court split over Bayer's fight against Roundup lawsuits - Reuters
Google News
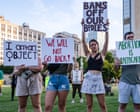
A Tennessee woman needed an abortion to save her life. She then joined a lawsuit against the state’s ban
World news | The Guardian

Ron DeSantis Aims to Add Four Republican House Seats in Florida Redistricting Push
NYT > Top Stories

Iran court upholds death sentence for protester, 25-year term for daughter
World News

Missouri and Illinois Face Severe Storms and Tornado Threat
NYT > Top Stories
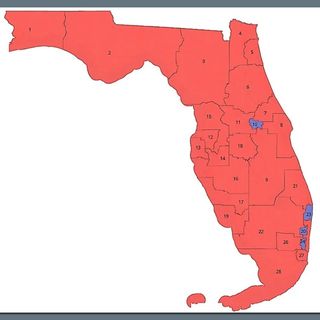
DeSantis unveils gerrymandered Florida map as redistricting war rages
Axios