Fixing LLM Writing with Distribution Fine Tuning
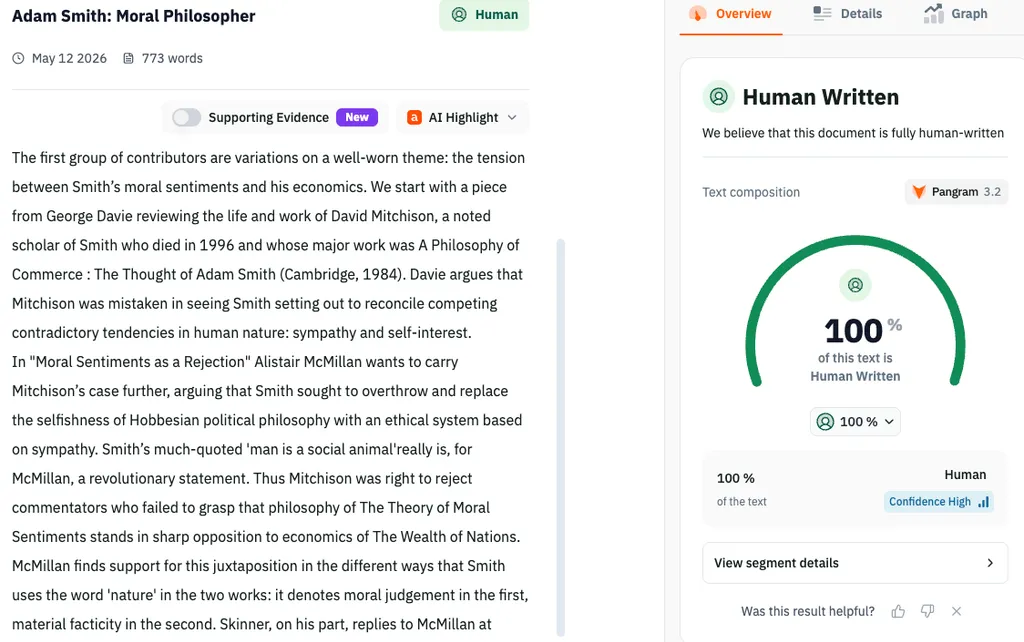
A new training algorithm called Distribution Fine Tuning (DFT) has been developed to improve the writing quality of language models. DFT significantly enhances the distribution of model outputs, resulting in better creativity, coherence, and clarity compared to traditional Supervised Fine Tuning (SFT). The model trained with DFT has been shown to produce outputs that are indistinguishable from human writing according to a detection tool.
- ▪Models trained with Distribution Fine Tuning (DFT) show a 49% improvement in Maximum Mean Discrepancy (MMD) and a 63% improvement in Judge Model Quality (JMQ).
- ▪The DFT algorithm improves creativity scores by 164%, coherence by 28%, and clarity by 16%.
- ▪Outputs from the DFT-trained model were scored as 100% human written by the Pangram AI detector.
Opening excerpt (first ~120 words) tap to expand
Abstract/TLDR: LLMs are notoriously formulaic at writing, overusing certain tokens or phrases. I show that models trained with SFT fail to match the distribution of the training data by using Maximum Mean Discrepancy (MMD), Judge Model Quality (JMQ), and L2 Token Distribution. To fix this, I created a new training algorithm, Distribution Fine Tuning (DFT), an LLM post training step that makes the distribution of model outputs better match the training distribution (improving MMD by 49% and JMQ by 63%). The model trained with DFT is much better at writing than an SFT baseline, improving creativity scores by +164%, as well as coherence (+28%), clarity (+16%), meaningful detail (+146%) and it does not have any overused “slop signs” like too many emdashes, or “it’s not X, it’s Y”.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Rosmine ML Blog.
Discussion
0 commentsMore from Rosmine ML Blog





