Compute Optimal Tokenization: Scaling Laws for Data Compression in LLMs
The article discusses findings on optimal tokenization for data compression in large language models (LLMs). It highlights that the ideal bytes-to-parameter ratio remains consistent across various compression rates and compute budgets. Additionally, the optimal compression rate varies by language, with implications for training models in different linguistic contexts.
- ▪The optimal ratio between bytes of data and model parameters is approximately constant across varying compute budgets and compression rates.
- ▪At each training compute budget, there is an optimal compression rate that minimizes loss, which decreases as the training budget increases.
- ▪The optimal bytes-to-parameter ratio and compression rate vary across different languages, showing correlation with the Parity metric.
Opening excerpt (first ~120 words) tap to expand
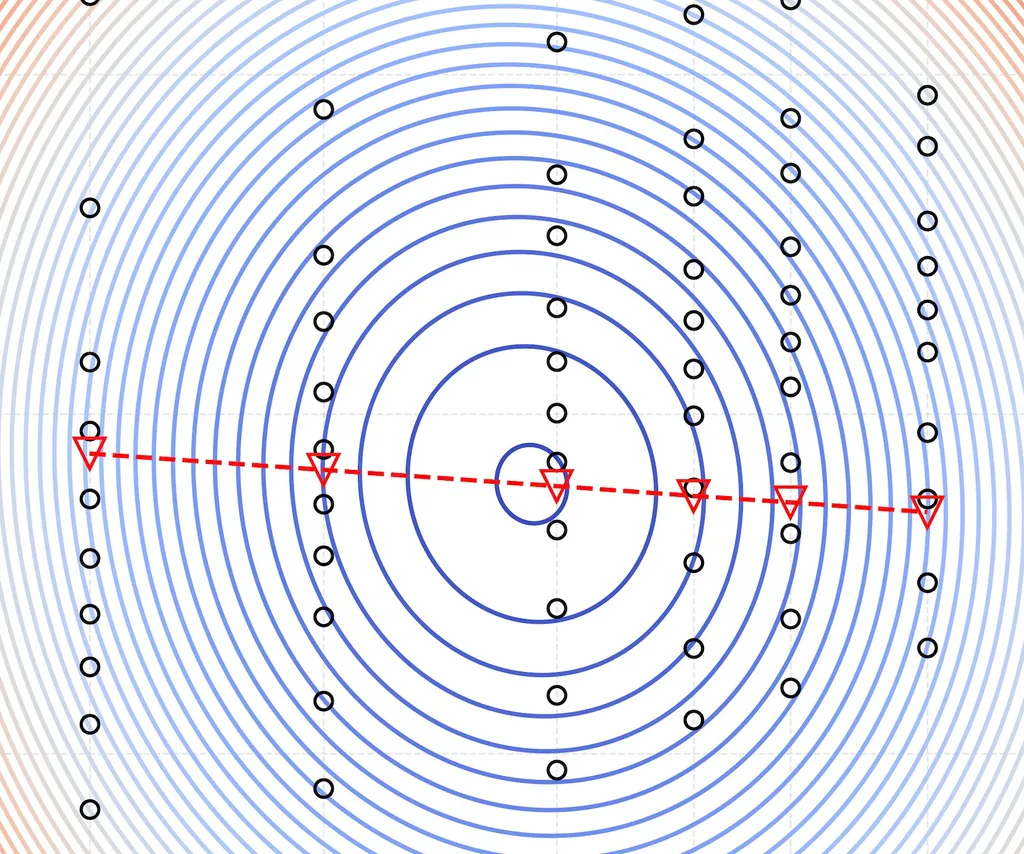
[F1] Optimal Data to Model Size For a fixed compute budget (1e20 FLOPs), we plot loss against compression rate and bytes per parameter ratio. This yields a 3D IsoFLOP: The bowl-shaped IsoFLOP surface shows that, for every compression rate, the lowest loss is achieved at roughly the same bytes per parameter ratio (triangles). Interactive version of the plot above. You can rotate it and hover over points to check loss, compression, and bytes per parameter values: We observe that the optimal bytes per parameter ratio remains nearly constant across different compression rates. Finding 1 The optimal ratio between bytes of data and model parameters is approximately constant across varying compute budgets and compression rates.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Github.
Discussion
0 commentsMore from Github