Benchmarking a Bug Scanner
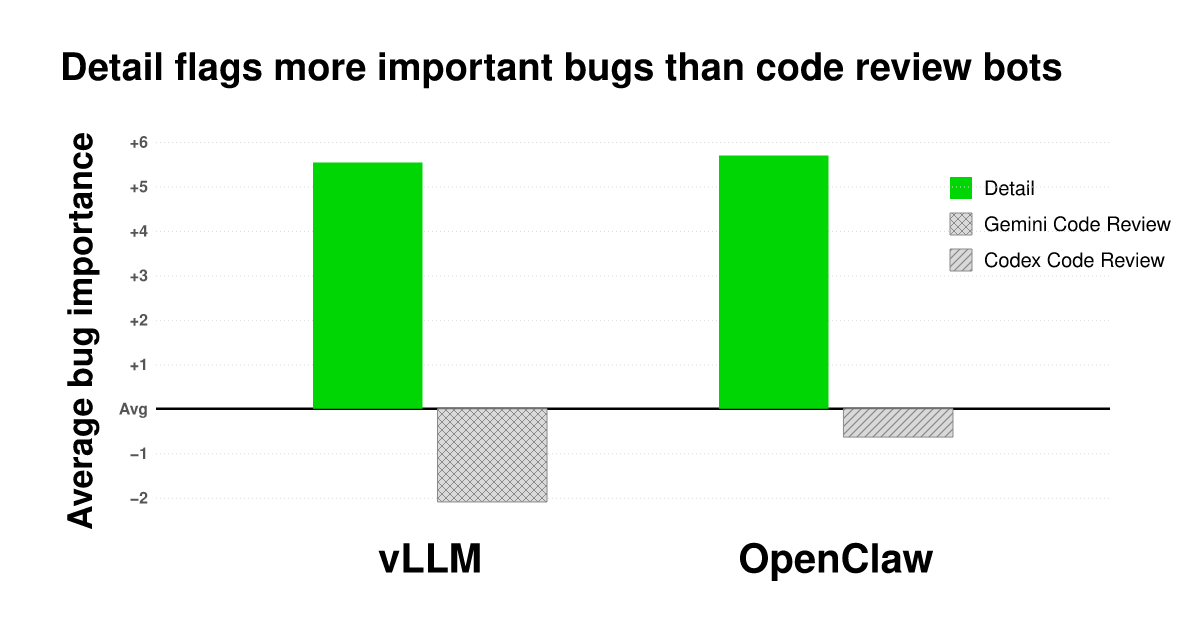
The article describes a benchmark comparing a new bug scanner called Detail against code review bots in detecting important bugs in the OpenClaw and vLLM codebases. Using Sonnet 4.6 as a judge, the study evaluated the relative importance of bug findings by conducting pairwise comparisons and applying a Bradley-Terry model to rank them. The results showed that Detail's findings were ranked higher in importance than those from code review bots, particularly when findings were summarized to reduce bias from detailed evidence.
- ▪Detail is a new bug scanner designed to identify high-importance bugs while minimizing noise in codebases.
- ▪The benchmark compared bug findings from Detail and code review bots over a one-week period in OpenClaw and vLLM.
- ▪Sonnet 4.6 was used as a judge to compare pairs of bug findings and determine which was more important for engineers to investigate.
- ▪Findings were summarized into one sentence each to reduce bias caused by the depth of Detail's original reports.
- ▪A Bradley-Terry model was used to generate global importance rankings based on the pairwise judgments.
Opening excerpt (first ~120 words) tap to expand
2026-04-30 · Sachin IyerBenchmarking a Bug ScannerWe ran a tournament pitting Detail's findings against thousands of comments from code review bots.We’re all coding with agents now, but delivering high quality software at 10x velocity remains an open problem. Code review bots are an important start, but a lot of bugs are still landing in production. Even top products are accumulating a layer of low-grade brokenness.1 We need new ways to make products secure and high quality.We built a new kind of bug scanner to solve this problem.The hard part about building a bug scanner is that any meaningfully complicated codebase has many thousands of bugs, and the vast majority don’t matter. You want to reserve human attention (and your tokens) for the bugs that matter.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Detail.
Discussion
0 commentsMore from Detail





