AI commerce needs an MLPerf – early attempt at one
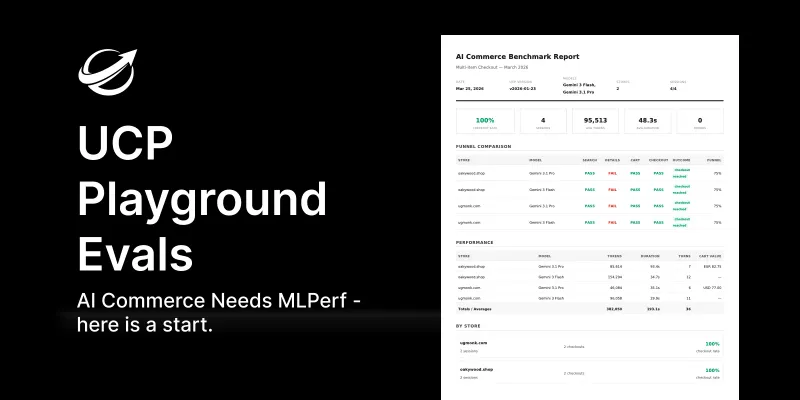
AI commerce currently lacks a standardized, neutral benchmark to evaluate how well online stores work with AI agents like Claude or GPT, leading to unverifiable vendor claims. Similar to how MLPerf transformed machine learning and Lighthouse improved web performance, a shared evaluation framework is needed for agentic commerce to mature. UCP Playground Evals is an early attempt at such a benchmark, offering reproducible, cross-store and cross-model testing of shopping interactions using multi-turn conversational sequences.
Opening excerpt (first ~120 words) tap to expand
Published on April 30, 2026 · 12 min read AI Commerce Needs MLPerf — and Here's an Early Attempt Benji Fisher Validating a UCP manifest takes a second. Scoring it for agent-readiness takes another. Neither of those answers the harder question: when a real frontier agent — Claude or GPT or Gemini, picked by a user three weeks from now — walks up to your store with an ordinary shopping prompt, does it actually complete a checkout? Compared to the next implementation? Across the models people are actually using? Today there's no shared way to find out.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Hacker News - Newest: ""AI" "LLM"".
Discussion
0 commentsMore from Hacker News - Newest: ""AI" "LLM""


